July 17, 2020
Four Ways to Implement a Universal Semantic Layer
I am a software engineer and I like abstractions. I like abstractions because done correctly an abstraction will factor complexity down to a level where I don’t have to spend any brain cycles thinking about it. Abstraction lets me work with a well thought out interface designed to let me accomplish more without having to always consider the system at a molecular level.
It turns out business people also like abstraction. This shouldn’t be surprising as businesses model complex real world concepts where the details matter. From calculation to contextual meaning, abstraction helps with correctness and understanding.
Take for example a simple definition such as an “Employee”. Does that include contractors? Remote people? How about a known, simple formula for Present Value with Compounding:
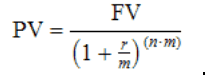
What is “Net Sales”? Is it net of invoice line-item costs and/or net of rebates? A small use case may contain tens of these calculations while a departmental model may contain hundreds. Without some level of abstraction, business is beholden to IT to generate and run reports or risk making big, costly and worst of all hidden mistakes. Can you afford to have each of your employees independently trying to replicate this logic correctly in their spreadsheets and reports? Will you be able to catch the subtle yet impactful errors?
In business intelligence (BI), also sometimes referred to as analytics, the key abstraction used in the majority of implementations is called the “semantic layer”.

Semantic, in the context of data and data warehouses, means ‘from the user’s perspective’; which sounds like a nice clean solution to a nasty unbounded complexity problem.
The semantic layer is not entirely new. In fact the concept was originally patented in 1991 by Business Objects and was successfully challenged by Microstrategy in 2003.
So, a Semantic Layer sounds great, what’s the catch?
Check out this simple search I did for ‘semantic layer’

How many semantic layers do you need? (Hint: The correct answer is 1). Remember, the semantic layer is an abstraction and while having multiple abstractions for the same concept is sometimes right and useful, most of the time it goes against the engineering mantra of DRY (Don’t Repeat Yourself).
What has Changed?
To stay great, great ideas must evolve. The concepts of a BI semantic model introduced almost 25 years ago have been largely static. AtScale believes the value of a modern BI platform is in addressing known shortcomings and innovating on what originally made the semantic layer great: it is a force multiplier for data consumers. In-depth knowledge of calculations and underlying data structure took a backseat to generations of useful operational reports, dashboards and other analysis build by folks that understand the business domains and not math.
The big changes in the past 10 years that affected data and its semantic layer have been in:
- Volume
More data is being generated. Most companies in the US have 100 terabytes of data. In 2020, it is estimated that 40 zettabytes of data will be created. These are big numbers that are growing quickly. The value of coupled with aggregates (a topic I’ll cover in a future blog) is in both reduced maintenance (no need to constantly work on ETL pipelines) and ability to more quickly analyze these massive amounts of data. Data is not going to atrophy, it will only grow. Are you prepared to handle the volume coming at you? - Velocity
More data is coming in faster and faster. Older Semantic Layer approaches that had a static build phase are too slow to keep up with the onslaught of data today and into the future. Through working with the biggest companies in the world, we developed the Adaptive Cache (an AI approach to aggregates) which can automatically map from source to Aggregate and has the ability to perform incremental updates. The end result is that the business has access to the most recent data collected without IT being burdened or the business waiting. It’s about speed; how fast can you respond? - Variety
More types of data are introduced every day. A modern Semantic Layer can make semi-structured data look structured; as though it is relational behind its abstractions. This means business users can keep using your standard visualization tools that have no concept of new or machine-generated underlying formats, like JSON or key-value pairs, without the need for complex, hard to maintain, no-value-adding repetitive data movement / ETL. No need to retrain end-users on a new visualization UX. they can continue to use their Tableau, Excel, Qlik and the other tools that they’ll only give up when you pry them from their cold, dead hands. - Veracity
This speaks right to the heart of the Semantic Layer. Uncertainty comes in many forms, and business users have lost faith in the data they use to make decisions. The abstractions provide proven, tested structures and calculations that consumers can trust.
The Upside
The Semantic Layer isn’t a single abstraction, it is a grouping of abstractions used to address different problems. Semantic Layer allows for improvements in the following:
- Usability/Understandability/Acceptance
One of the biggest complaints from the business is that it takes way too long for IT to build or alter reports for them. They want to take the helm and control their own destiny. A well designed semantic layer with agile tooling allows users to understand how modifying their query will result in different results, while at the same time giving them independence from IT – freedom from IT while still having confidence their results will be correct. - Security & Governance
In this day and age, the enterprise has strong, and sometimes regulatory, requirements that they track and know ‘who’ saw ‘which’ data and ‘when’. The entirety of our “True Delegation” product came from a partnership with our fantastic customers and allows them to know who, what, and when in a tightly secured data lake. Prior incarnations of the semantic layer lacked the ability to track the lineage of data from row level to every aggregate managed by the software. - Capability
More mature and sophisticated analytics + modern BI vendors introducing advanced capabilities = abstraction required. As we complete our vision of what a modern BI platform is we find ourselves pulling in concepts that were once in the realm of data science. These new generation of predictive and machine learned analytics are both not support by BI viz tools, and too complex to expect business users to understand the implementation instead of just the desired outcome. - Correctness
The Semantic Layer excels at being able to create sophisticated SQL and often multiple SQL statements in response to a very simplified set of user gestures. The semantic layer must understand how to deal with database loops, complex objects, complex sets (union, intersection), aggregate table navigation and join shortcuts. By applying rules to define database complexity and ambiguity the generation of the SQL guarantees that if two users ask for the same information, they will get the same results – this is the most important aspect of the Semantic Layer, allowing an organization to define a single version of the truth. - Latency Reduction
Latency, also thought of as “time to insight” is how long after the data lands somewhere that it can be used to make decisions. In legacy BI solutions there was often a build process that could take anywhere from minutes for small data, to days/weeks for large data. We’ve spent a lot of time building an integrated set of technologies that enables new data landing in your data warehouse to be queryable by your BI tool within minutes regardless of size. There are no full-build or full-rebuild times to wait for, and no manual ETL processes. The Semantic Layer metadata includes data lineage which can be used for both governance as discussed, but also to map from source fact tables to all the downstream temporary data structures that are used to increase performance by updating them incrementally. - Performance & Scale
One reason Microsoft introduced the tabular model was to overcome performance issues, but this added to the complexity. Which model should I use? In Microsoft’s own words:
“Both multi and tabular have some strengths and weaknesses today and one is not clearly superior to the other.” – technet
We took a different approach and invented technology in the Adaptive Cache that gives performance regardless of underlying structure, we don’t care if your model is a snowflake, a star, or purely OLTP. You design your data, we make it perform by always generating the best SQL possible and using the most appropriate aggregates. This means less ETL and data wrangling and more reporting and analysis. Every real world big data use case we encounter gives us more insight into how to make data faster and more accessible.
The Downside of a Semantic Layer
The biggest downside of a Semantic Layer is you have to build, maintain and manage it. The layer must be kept in sync with any database changes that occur. However, at the end of the day, it’s a lot easier to maintain a semantic layer of definitions than it is to maintain 1,000’s of reports.
The second downside is that data often exists in multiple backend systems or operational data stores (ODS). Thus, you have to make and maintain multiple semantic layers; one semantic layer either per system or per BI tool.
On a bright note, our view is that the world is moving to data lakes, and data virtualization which will allow for the creation and maintenance of a single semantic layer. This will become a solved problem in 2017.
The Trend
In response to previous generations of Semantic Layer platforms’ lack of usability, complexity, and IT’s inability to service requests in a reasonable timeframe the market has moved to embrace a set of data discovery tools: the Tableaus, Qliks, etc., which have done away with centralized Semantic layers all together. These tools make connecting into relational data sources a breeze. The fallout is that it means business users will need a better understanding of building queries, which arguably wasn’t necessary with a good Semantic Layer.
The BI users pursuing the other 20% of analysis via these data discovery tools sidestepped the older fixed-data warehouse model. Logic is now distributed and duplicated, complex personal models arose that include combinations of data from the warehouse and other systems. Eventually this gave way to hub-and-spoke models and data management became a major problem. Users were given enough rope to shoot themselves in the foot.
We love the data discovery tools, however we believe they were designed for discovery, not necessarily for core BI. The use arose because sophisticated users had freedom and power that couldn’t be shut out by corporate IT.
A Modern Solution
Our solution to the problems that users have with the prior generation and approach is to make large scale analytics more agile. So we asked ourselves:

As AtScale leads the modern age of BI, the Semantic Layer is more important as we increase the number of items we can specify.
Do You Need a Universal Semantic Layer?
Businesses will have to define a semantic layer, no matter what. If you don’t have experts do it, all your end users will do it for themselves in Tableau, Qlik, Excel or whichever front end they are using. For established and often shared models, pushing down the definitional layer will increase adoption, time to analysis and correctness.
Current BI tools have focused on giving users flexibility and that often means the governance model is “no management required”. Many folks we talk to are coming from a world where they write and maintain complex ETL pipelines to generate numerous extracts that are fed to BI tools. Not only is this a maintenance headache, this gives the governance people a massive myocardial infarction.
Data discovery is a valid BI use case that many across your organization are demanding, aka the other 20%, where the current generation of tools excel. As a leader in your BI groups, either on the business or tech side you, have to have a good sense of when you need Semantic Layer or Data Discovery because one size does not fit all.
Your Turn!
Interested in learning more about AtScale’s Universal Semantic Layer? Follow us on LinkedIn and check out a technical overview of AtScale’s Universal Semantic Layer here.
ANALYST REPORT