March 7, 2019
Gartner Magic Quadrant for Business Intelligence (BI) 2018: The Good, The Bad, The Ugly…
As more and more enterprises adopt Hadoop as their next generation data platform, the demands of traditional enterprise workloads, including support for Business Intelligence use cases, are creating challenges. While Hadoop excels at low-cost distributed storage and parallel data processing, interactive support for BI-style queries remains a challenge. Additionally, multi-dimensional queries often demand complex OLAP-style calculations and functions. In this post we will share how AtScale helps to bridge the gap between Business Intelligence users and data that resides in Hadoop.
In many typical business analyses or applications it is important to be able to directly query the first or last value of a particular metric across a hierarchy. For example:
- What was the starting or ending price of a security during a particular day
- What were inventory levels for a SKU at the beginning and end of the month
- What was the first and last payment amount for a loan agreement
Not Always as Easy as it Sounds
Executing such a query using SQL may involve complex queries consisting of unions, sub-queries, and/or temporary tables. In MDX (Multidimensional Expression Language) such a query is easier to support, given MDX’s rich support for analytical queries and hierarchical representation. AtScale has implemented support for First Child and Last Child measures in a way that supports BOTH SQL and MDX clients, which means that virtually any data visualization client can take advantage of this advanced functionality.
The following sections describe how you can create and query First and Last Child measures, in Hadoop, across BOTH SQL and MDX clients, using the AtScale Intelligence Platform.
The Basics
The example below is based on a slightly modified version of Microsoft’s Adventureworks Database. This data has been loaded into a Hadoop cluster and modeled using Hive. Our fact table for this analysis is the factinternetsales table, as shown here. For purposes of this document we will focus on creating 3 metrics:
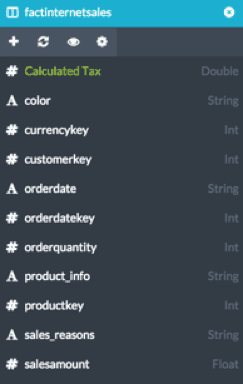
- Sum of Order Quantity
- Order Quantity at End of Period
- Order Quantity at Beginning of Period
We also will use a Date Hierarchy to analyze our Order Quantity metrics over time. Like any fully-functional OLAP server, AtScale provides rich support for hierarchies, including multiple hierarchies per dimension, secondary attributes and role-playing relationships.
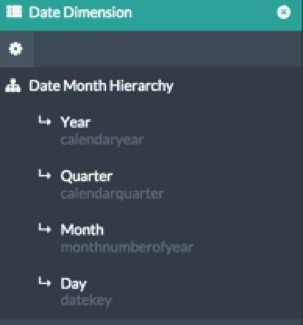
The date hierarchy for our example is shown here. For our sample analysis we are going to figure out the values of order quantity for each month, along with the value of order quantity on the first and last day of each month.
Creating Measures and Relationships
The first step of our modeling process is to create the appropriate relationship between our fact table and the data dimensions. This can be done in AtScale’s Design Center by simply dragging the orderdatekey column from the fact table and dropping it on the “Day” level (with key datekey) of the Date Hierarchy.
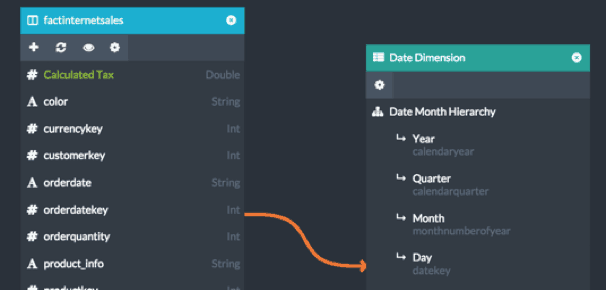
Once this relationship is in place, three measures are created. This can be done by dragging the desired source column for the measure – in this case orderquantity – onto the Measures panel of modeling canvas. In addition to created a standard SUM metric, designers can specify if the measure is a semi-additive metric, and if so, what type and across which dimension.
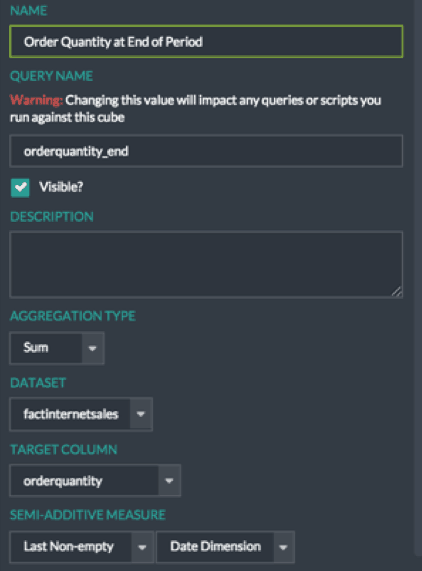
Currently AtScale provides built in support for First Non-Empty and Last Non-Empty semi-additive measures.
Note that this measure has been flagged as a “Semi-Additive Measure”
Analyzing the Data
Now that the measures and dimensions for this cube have been created, they can be queried using a data visualization front end like Tableau or Microsoft Excel.
In Tableau, the AtScale cube can be accessed using an automatically-created TDS (Tableau Data Source) file that includes the hierarchical structure as designed in the cube. Once open, it’s simple to create the following report by dragging and dropping our Order Quantity metrics and the Month level of the data hierarchy onto the canvas. This report now shows the Total Sum of Order Quantity, as well as the values for the First Child (first day) and Last Child (last day) of each month.
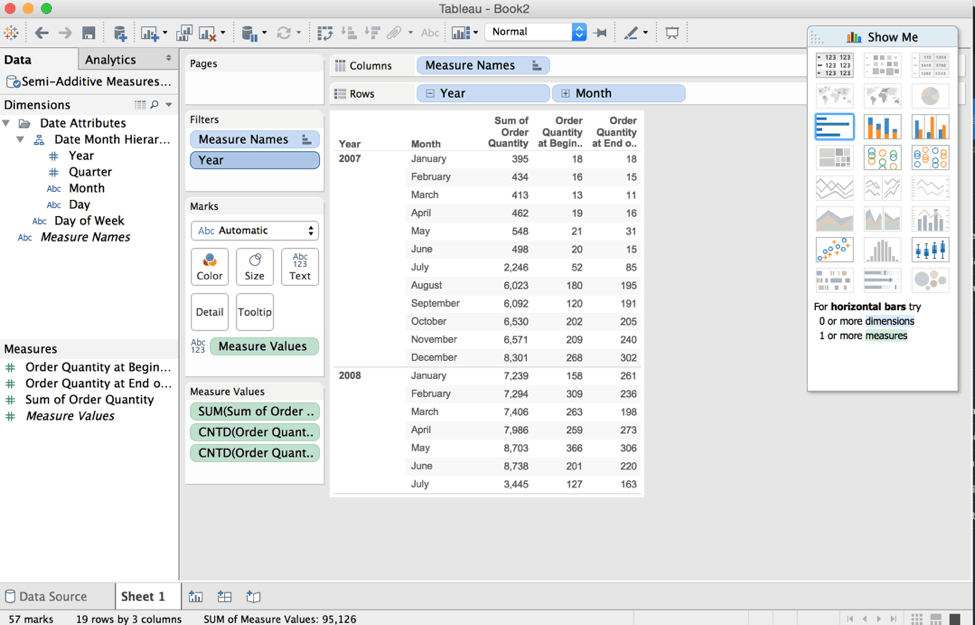
To confirm the validity of the results, we can ‘drill down’ into the daily view of the data for the month of February 2008. As the results show, the value of Order Quantity of the first day of the month is 309 and on the last day of the month is 238 – this is consistent with
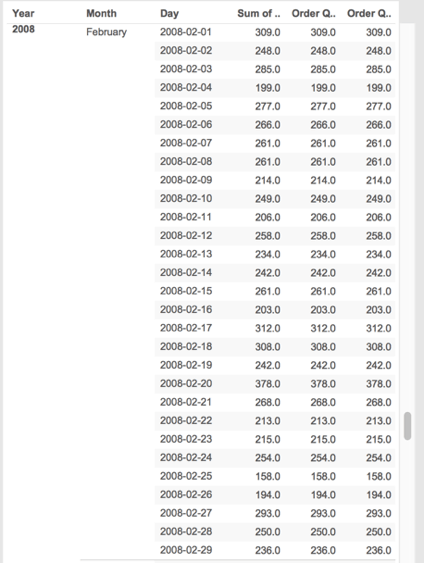
the results of our First Period/Last Period query at the monthly level.
It’s worthwhile at this point to comment on the simplicity of doing this analysis in Tableau versus the complexity of the query that needs to be executed on the underlying raw data tables in Hadoop.
Because AtScale abstracts away the complexity of this query, this means that Tableau (or any other system or person querying AtScale in SQL) can submit a very simple query, like this one:

Without AtScale, this query would need to be written, by hand, as follows:

But Wait, That’s Not All
In addition to this data being accessible via a SQL query, generated by Tableau, by hand, or by another SQL client, this exact same cube model is accessible by clients that utilize the MDX query language as well. For example, using an MDX client such as Microsoft Excel, we can access the exact same cube in AtScale, and arrive at the same results.
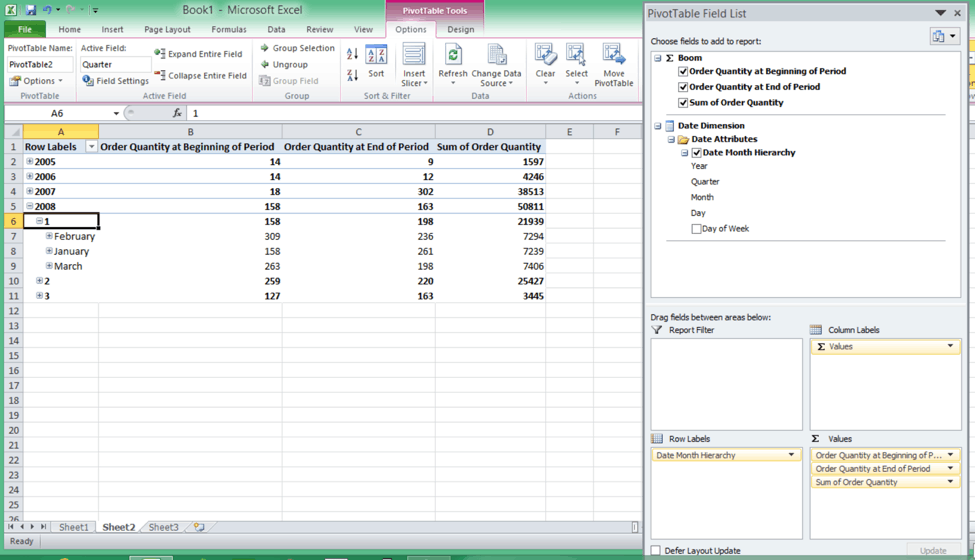
In the above example, Excel is connecting to the AtScale cube as if it were a SQL Server Analysis Services data provider (using the XMLA protocol), and it’s now possible to interact directly with the data on the underlying Hadoop deployment in live query mode. Because the underlying semantic data model is shared regardless of the dialect used (SQL or MDX) the results across all tools are identical.
An example of the MDX generated by the Excel pivot table above and submitted to the AtScale engine is shown below:

In Summary
- The traditional Multi-dimensional BI (aka OLAP) approach provides support for very common and necessary analytical use cases, including hierarchical data representations and time-relative (First and Last Child) measurements.
- Up until now, this wasn’t easy to replicate in Hadoop.
- The AtScale Intelligence Platform supports these concepts directly on top of data sets that are stored in a Hadoop Hive Warehouse, effectively transforming a Hadoop cluster into a Scale-Out BI Server.
- In addition to providing an intuitive and simple design process for AtScale Virtual Cubes, the AtScale platform supports virtually any Business Intelligence or Data Visualization front-end by providing support for both SQL and MDX query languages against a shared, consistent semantic layer.
I hope you find this interesting and helpful. Let me know what you think, ping me if you have questions, or visit atscale.com to learn more.
NEW BOOK