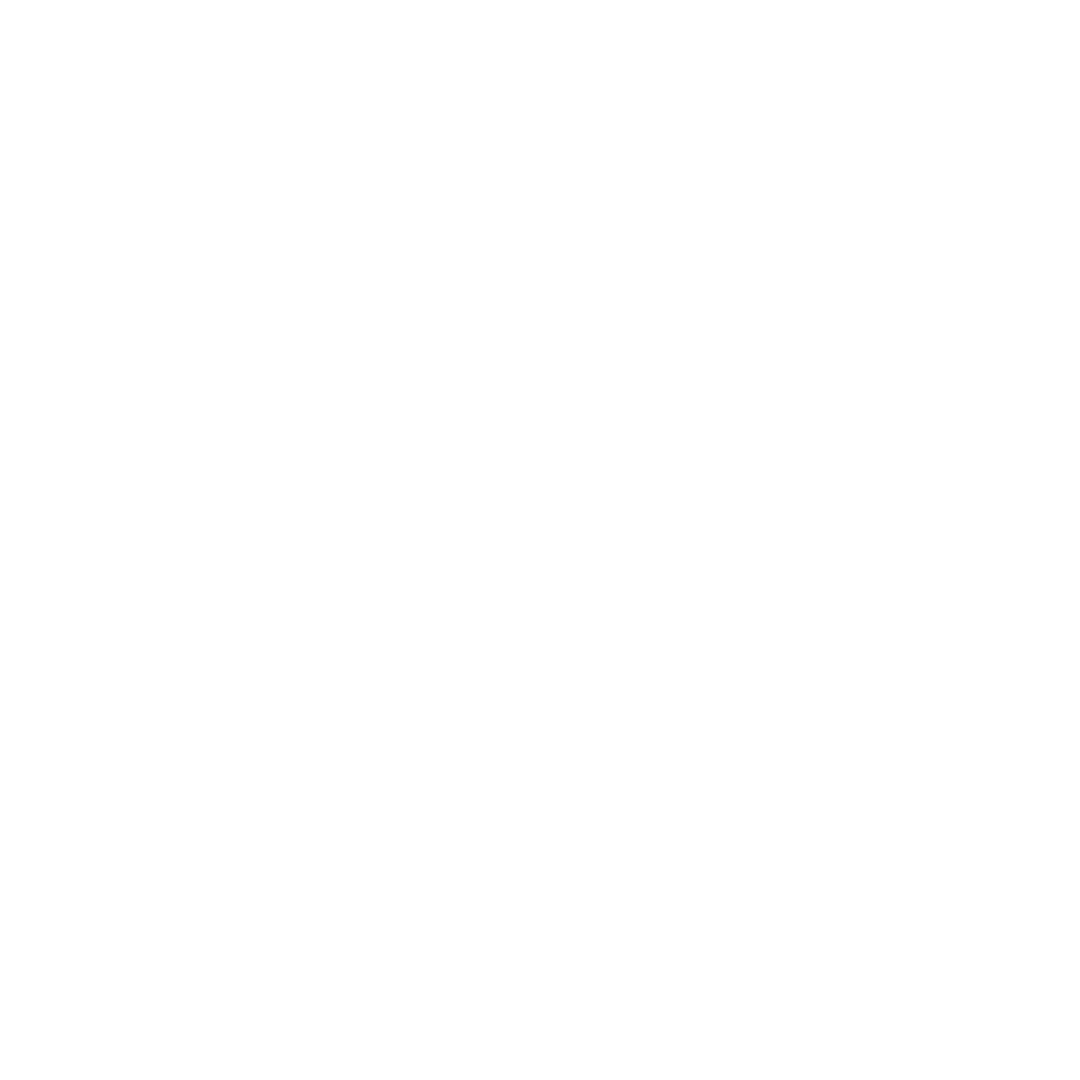A Semantic Layer for:
The leading platform for governed, AI-ready metrics at scale




Connect any data source to any AI/BI tool without moving your data
A semantic layer maps complex data to familiar business terms, like product, revenue, or customer, to create a unified, governed view of data across your organization. It empowers users and AI agents to access accurate insights autonomously.
Redshift

Databricks
Google Big Query

Data Warehouse/ Lakehouse

Snowflake

Azure Synapse

Cloudera
Semantic Layer

Data Democratization & Governance

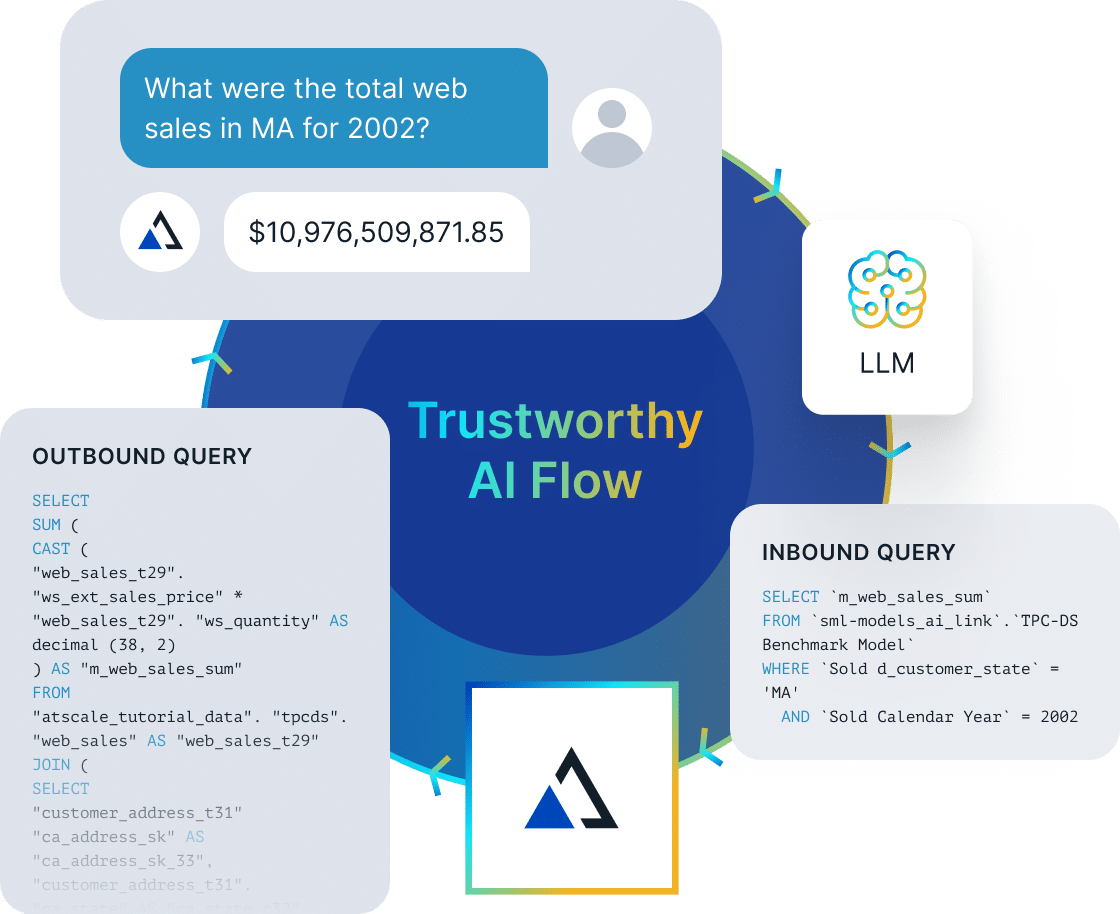
Cloud Cost Management & Performance

Enabling Gen AI with Business Context

Gen AI / LLM
BI Tools

AI Agents / Chatbots

Applications

BI Tools
AI Agents / Chatbots
Applications
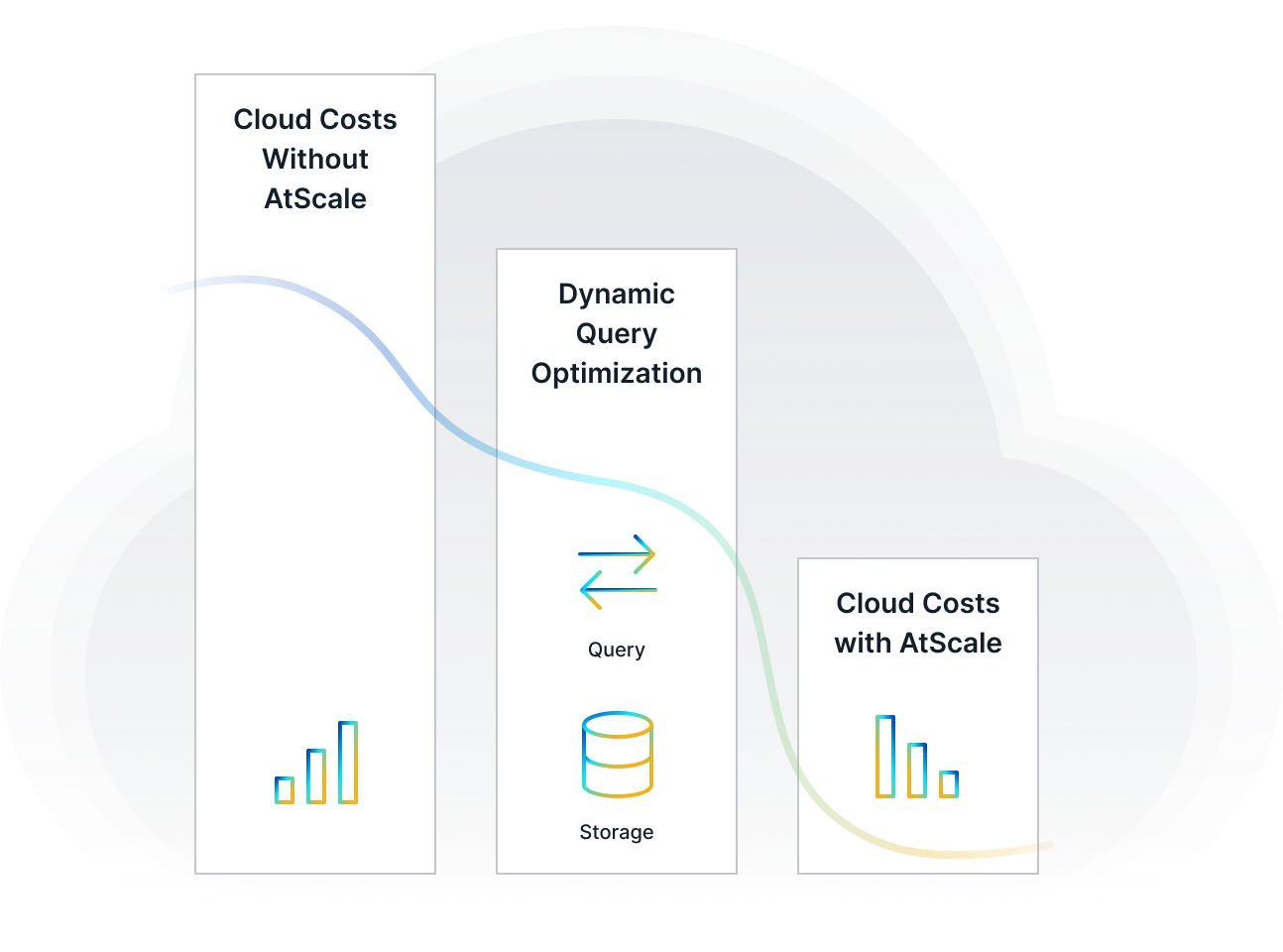
Modern Analytics for Every Role and Data Stack
The Universal Semantic Layer for Enterprises
Empower teams with secure, real-time data access, governed semantic modeling, and universal compatibility across tools and protocols.


Agentic AI Ready

Open-Source Semantics

Live Cloud Connectivity

Universal BI Integration

Governed Semantics for Agents & Humans
Multi-Dimensional Business Logic
Unify Your Data Ecosystem
Multi-protocol deep integrations that support SQL, MDX, DAX, Python, and REST protocols, integrating seamlessly with various BI tools or visualization platforms. Learn More -->