







Build Composable Analytics
Empower distributed teams to create, govern and share business definitions using an object-oriented approach. Assemble sophisticated business-friendly models with plug-and-play semantics using a governed library of semantic objects including dimensions, metrics, calculations and much more.
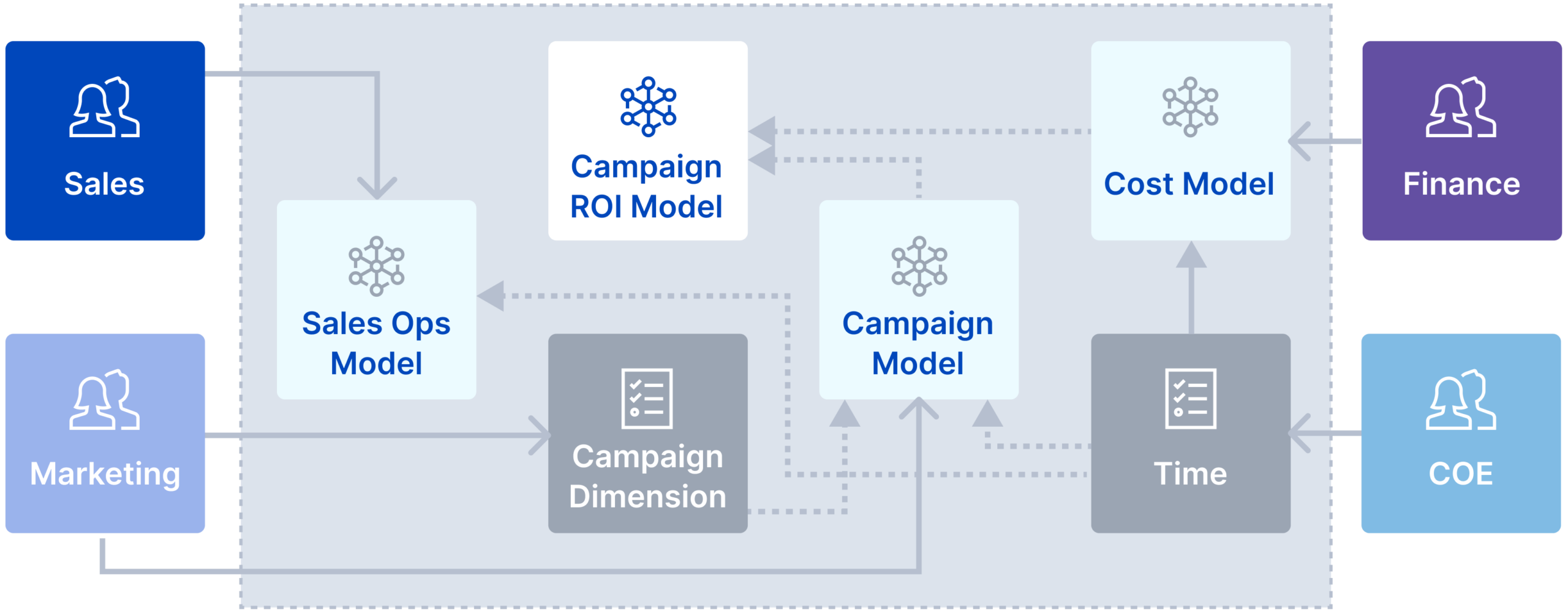
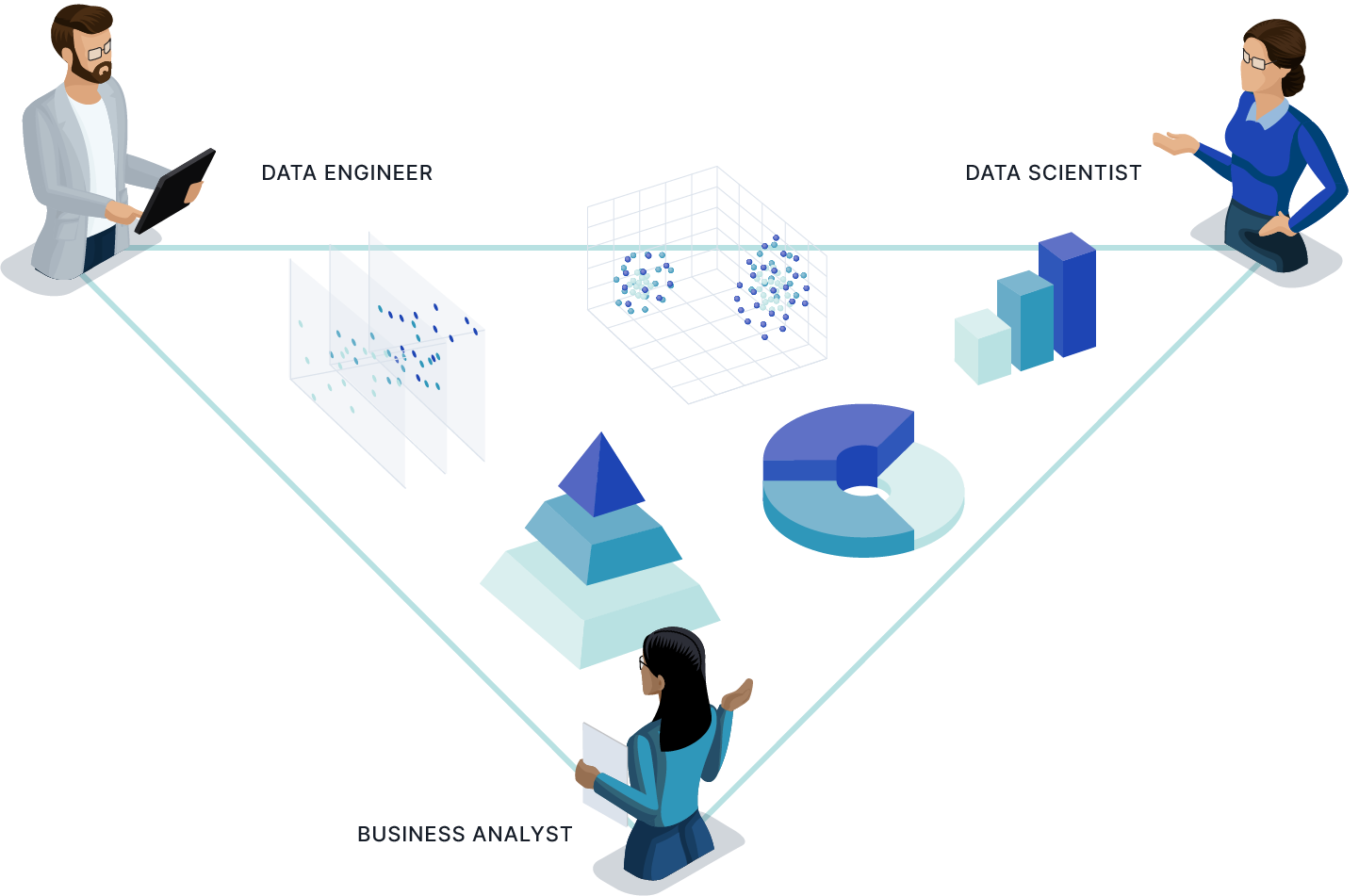
Drive Collaborative Modeling for Multiple Personas
Build semantic models that span multiple business domains and analytics personas. AtScale’s code and no code based modeling architecture provides a common library for business analysts, data engineers and data scientists to collaborate on building and sharing a consistent set of semantic objects.
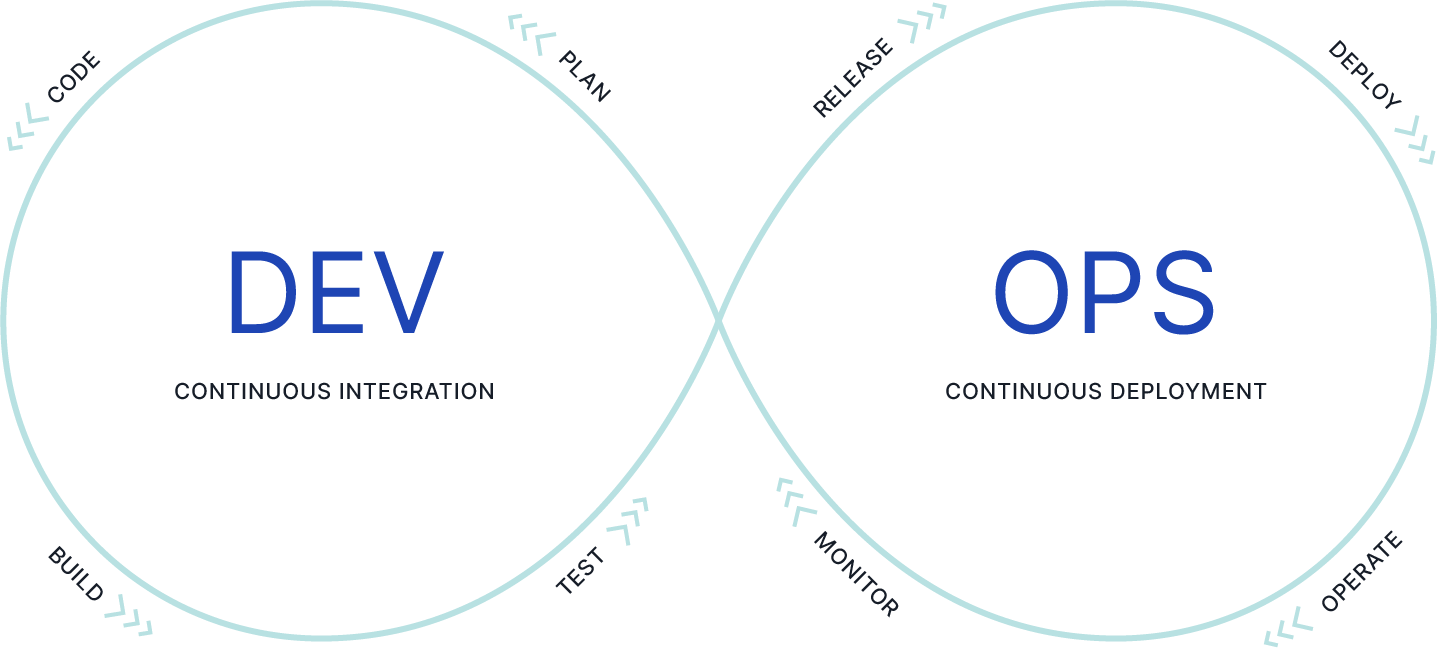
Build Data Products like Software with CI/CD
AtScale’s semantic models are based on Semantic Modeling Language (SML), an object-oriented, YAML-based modeling language. With your Git-compatible repository as the source of truth, you can apply the same software development life cycle (SDLC) you use for managing software projects to semantic model development.


Analytics Modernization at Fortune 100 Multinational Food Producer, Tyson Foods
AtScale partnered with the data team at Tyson to ensure continuity of BI and reporting through the transition from Hadoop to Amazon RedShift and ultimately to Google BigQuery. Along the way, Tyson leveraged the AtScale semantic layer to lay the foundational building blocks to enable self-service BI and respond more nimbly to change.
Delivering Business Impact
AtScale complements investments in modern cloud data platforms by accelerating BI workloads, simplifying creation of complex queries, and virtualizing analytics and AI/ML data pipelines.
Acceleration in BI Query Speed
8X
Reduction in Compute Consumption
3X
Reduced Time to Insight
10X
Improved Resource Productivity
4X